
DevBlackCat
정보처리기사: 물리 데이터 베이스 모델링 본문
728x90
데이터 무결성
- 데이터 정확성, 일관성, 유효성을 보장하는 기능
무결성 종류
① 개체 무결성(Entitiy Integrity)
- 모든 릴레이션은 중복되지않는 고유한 값인 기본키를 가져야한다.
- 기본키는 NULL을 가질수없다.
② 참조 무결성(Refetential Integrity)
- 외래키는 NULL이거나 유효한 참조 릴레이션의 기본키와 일치해야한다.
제약조건
| 종류 | 설명 |
| 제한 (Restrict) | 문제의 연산을 거부한다. |
| 연쇄 (Cascade) | 참조된 튜플 삭제 시, 참조하는 튜플도 함께 삭제한다. |
③ 도메인 무결성(Domain Integrity)
- 모든 속성값은 정의된 도메인에 속해야한다
- ex)성별 컬럼에 남,녀 외에 의미없는 데이터가있으면 안됨
④ 고유 무결성 (Unique Integrity)
- 릴레이션의 특정 속성 값은 서로 달라야 한다.
⑤ 키 무결성 (Key Integrity)
- 각 릴레이션은 적어도 하나의 키를 가져야 한다.
⑥ 릴레이션 무결성 (Relational Integrity)
- 삽입, 삭제, 갱신 등의 연산은 릴레이션의 무결성을 해치지 않도록 수행되어야 한다.
문제
참조 무결성을 유지하기 위하여 DROP문에서 부모 테이블의 항목 값을 삭제할 경우, 자동적으로 자식 테이블의 해당 레코드를 삭제하기 위한 옵션은?
CASCADE
키종류
키의종류 ★★(실기도 나옴)

- 기본 키 (Primary Key)
- 유일성 보장.
- 각 레코드가 고유한 식별자를 가짐.
- 후보,기본,대체 키
- 유일성과 최소성을 만족.
최소성: 키는 최소한으로 해라
| 종류 | 설명 |
| 후보키 (Candidate Key) | - 릴레이션에서 튜플을 유일하게 식별할 수 있는 속성들의 집합. - 반드시 하나 이상 존재해야 하며, 유일성과 최소성을 만족해야 한다. |
| 기본키 (Primary Key) | - 후보키 중에서 선택된 메인 키. - 특정 튜플을 유일하게 식별할 수 있으며, NULL 값을 가질 수 없고, 중복된 값을 가질 수 없다. |
| 대체키-보조키 (Alternate Key) | - 둘 이상의 후보키가 있을 때, 기본키로 선택되지 않은 나머지 키. |
| 슈퍼키 (Super Key) | - 튜플을 유일하게 식별할 수 있는 속성들의 집합이지만, 최소성을 만족시키지 않는다. |
| 외래키 (Foreign Key) | - 다른 릴레이션의 기본키를 참조하는 속성. - 릴레이션 간 참조 관계를 표현하는 데 사용되며, 참조 무결성 조건을 만족해야 한다. |
반정규화
- 정규화 후 성능향상이나 편의를 위해 의도적으로 중복을 허용하거나 데이터를 재구성 하는 방법 (★ 실기나옴)
순서
1. 반정규화 대상 조사
2. 다른방법으로 유도
3.반정규화 실행
분할 기준 ★
1. 범위 분할 (Range Partitioning)
- Partition Key의 연속된 범위로 파티션을 정의.
- 파티션 키 위주로 검색이 자주 실행될 경우 유용.
- 예시: 월별, 분기별 등.
2. 목록 분할 (List Partitioning)
- 특정 Partition에 저장될 Data에 대한 명시적 제어.
- 많은 SQL에서 해당 Column의 조건이 많이 들어오는 경우 유용.
- 예시:
- [한국, 일본, 중국 → 아시아]
- [노르웨이, 스웨덴, 핀란드 → 북유럽]
3. 해시 분할 (Hash Partitioning)
- 파티션 키 값에 해시 함수를 적용하고, 거기서 반환된 값으로 파티션 매핑.
- 데이터가 모든 파티션에 고르게 분산되도록 DBMS가 관리.
- 병렬 처리 시 성능 효과 극대화.
4. 라운드 로빈 분할 (Round Robin Partitioning)
- Data를 균일하게 분배해서 저장하는 방식.
5. 합성 분할 (Composite Partitioning)
- 위의 기술들을 복합적으로 사용하는 방법.
- 예시: 범위 분할 후 분할된 데이터를 해시 분할하는 방식 등.
클러스터 설계
- 자주사용되는테이블의 데이터를 디스크상 동일한 위치에 저장하여 효율을 향상시키는 물리적 저장 방법
- (자주 가는 가게가 서울 , 부산 인것보다 둘다 서울에 있으면 시간이 덜걸리듯이)
특징
- 그룹화된 데이터는,디스크 I/O 최소화
- 조인성능 향상
- 데이터의 분포도가 넓을 경우 유리
- 인덱스 생성시 성능향상
인덱스
- 검색 속도 향상을 위한 저장공간 활용 구조
1. 클러스터 인덱스 (Clustered Index)
- 테이블당 1개만 허용되며, 해당 컬럼을 기준으로 테이블이 물리적으로 정렬됨.
- 데이터는 기본적으로 오름차순으로 정렬 진행.
- 기본 키를 설정하면 자동으로 클러스터드 인덱스가 적용.
- 인덱스 자체의 리프 페이지가 곧 데이터.
- 데이터 입력, 수정, 삭제 시 항상 정렬 상태를 유지.
- 비클러스터형 인덱스보다 검색 속도는 빠르지만, 데이터 입력, 수정, 삭제 시에는 느림.
2. 넌클러스터 인덱스 (Non-Clustered Index)
- 테이블당 약 240개의 인덱스 생성 가능.
- 레코드의 원본은 정렬되지 않고, 인덱스 페이지만 정렬.
- 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터 위치를 나타내는 포인터(RID).
- 클러스터형보다 검색 속도는 느리지만, 데이터 입력, 수정, 삭제는 더 빠름.
3. 밀집 인덱스 (Dense Index)
- 데이터 레코드 각각에 대해 하나의 인덱스가 만들어짐.
4. 희소 인덱스 (Sparse Index)
- 레코드 그룹 또는 데이터 블록에 대해 하나의 인덱스가 만들어짐.
인덱스 구조
- 트리 기반 인덱스
- 비트맵 인덱스
- 함수 기반 인덱스
- 비트맵 조인 인덱스
- 도메인 인덱스
인덱스 컬럼의 선정
- 분포도가 좋은 컬럼을 선택 (10%~15%).
- 자주 조합되어 사용되는 경우 결합 인덱스를 생성.
- 가능한 수정이 빈번하지 않은 컬럼을 선정.
- 한 컬럼이 여러 인덱스에 포함되지 않도록 설계.
- 기본키 및 외부키가 되는 컬럼을 선정.
뷰
- 기본테이블에 유도된 가상테이블
- 실제 데이터를 저장하지않고 논리적으로만 존재
- 사용자는 뷰를 조작가능
뷰(View)의 개념
- 기본 테이블을 유도하여 기본 테이블과 유사한 형태와 조작을 가진다.
- 물리적 구현 없는 가상 테이블.
- 논리적 데이터 독립성 제공.
- 관리 용이 및 명령문 간소화 (필요한 데이터만 처리).
- 뷰를 통한 데이터 접근으로 안전 보호.
- 데이터 조작(삽입, 삭제, 갱신)에 제한 존재.
- 기본 테이블/뷰 삭제 시 관련 뷰도 자동 삭제.
- 생성은 CREATE, 삭제는 DROP 명령으로 가능.
뷰의 장/단점
장점
- 논리적 데이터 독립성.
- 다양한 사용자 요구에 대한 동시 지원.
- 간결한 데이터 관리.
- 자동 보안 제공 (접근 제어).
단점
- 독립적 인덱스 부재.
- ALTER VIEW 사용 불가.
- 뷰 조작(삽입, 삭제, 갱신 등)에 제약 존재.
백업
| 용어 | 설명 |
| 풀 이미지 백업 | - 전체 데이터 백업 |
| 차등 백업 | - 마지막 풀 이미지 백업 이후, 모든 변경사항을 백업 |
| 증분 백업- | - 마지막 풀 이미지 백업 이후, 점차적으로 변경된 사항 백업 |
| 실시간 백업 | - 변경사항을 즉시 백업, 분리된 스토리지에 실시간 복사 (장비 두대) |
| 합성 백업 | - 기본백업 + 후속 증분 백업으로 전체 백업 구성/통함 |
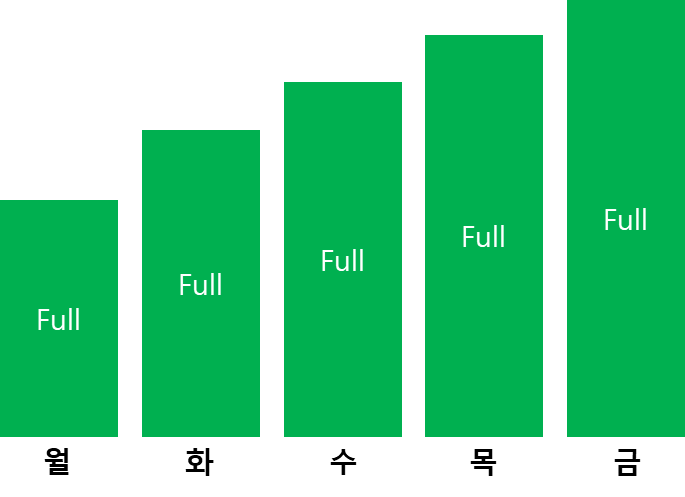
풀 이미지 백업
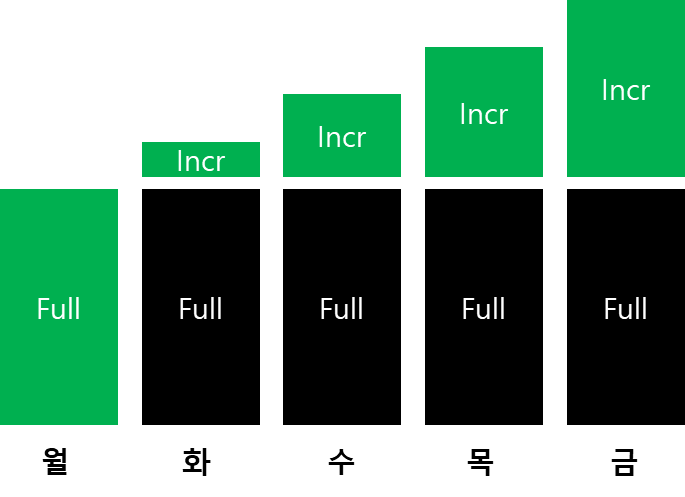
차등 백업
증분 백업
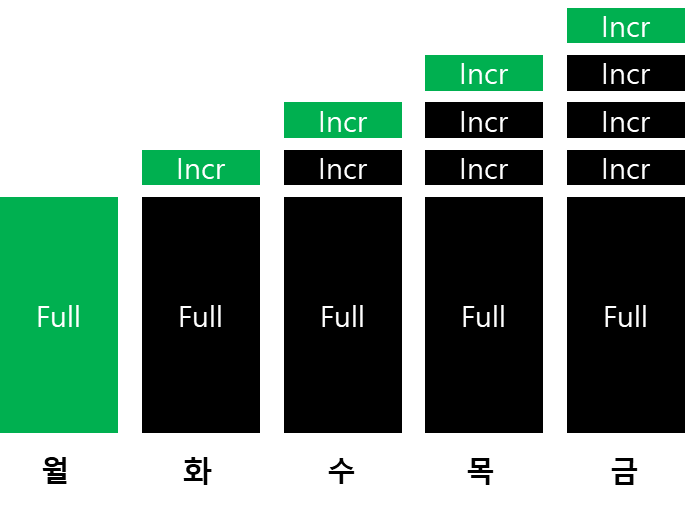
차등백업은 최초 풀 이미지 백업이후 변경사항을 하나로 저장하지만
증분 백업은 각각 하루 별로 변경사항을 저장한다.
재난 복구 전략 시 성과 지표
| 용어 | 설명 |
| RTO | - 업무 중단 부터 복구 및 재가동이 목표 - 업무 중단을 얼마나 허용할지 시간 (시간) |
| RPO | - 재해 발생후 데이터 손실 범위 - 데이터 손실을 얼마나 감당할지 시점 (데이터) |
| MTD | - 업무 중단의 최대 시간 |
RTO는 복구할수있는 목표시간이고, MTD는 장애를 허용하는 최대 시간으로 비슷하지만 기준이 조금 다름
그외 RP가 있는데 RP는 실제 업부 기능 복구 까지 걸리는 시간이다.
728x90
'정보처리기사 > 데이터베이스 구축' 카테고리의 다른 글
| 정보처리기사 : SQL 작성 (1) 완전정복!! (1) | 2024.12.07 |
|---|---|
| 정보처리기사 : 물리데이터모델 품질검토 완전정복!! (0) | 2024.12.07 |
| 정보처리기사 : 물리속성 설계 완전정복!! (1) | 2024.12.06 |
| 정보처리기사 : 물리요소 조사 분석 완전정복!! (0) | 2024.12.05 |
| 정보처리기사 : 관계 데이터베이스 모델 완전정복!! (1) | 2024.12.05 |
'정보처리기사/데이터베이스 구축' Related Articles
more

